作者:卢钧轶 (cenalulu) 本文原文地址:http://cenalulu.github.io/linux/numa
NUMA 简介
为什么要有 NUMA
在 NUMA 架构出现前,CPU 欢快的朝着频率越来越高的方向发展。受到物理极限的挑战,又转为核数越来越多的方向发展。如果每个 core 的工作性质都是 share-nothing(类似于 map-reduce 的 node 节点的作业属性),那么也许就不会有 NUMA。由于所有 CPU Core 都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个 die 上。于是 NUMA 就出现了!
NUMA 是什么
NUMA 中,虽然内存直接 attach 在 CPU 上,但是由于内存被平均分配在了各个 die 上。只有当 CPU 访问自身直接 attach 内存对应的物理地址时,才会有较短的响应时间(后称 Local Access)。而如果需要访问其他 CPU attach 的内存的数据时,就需要通过 inter-connect 通道访问,响应时间就相比之前变慢了(后称 Remote Access)。所以 NUMA(Non-Uniform Memory Access)就此得名。
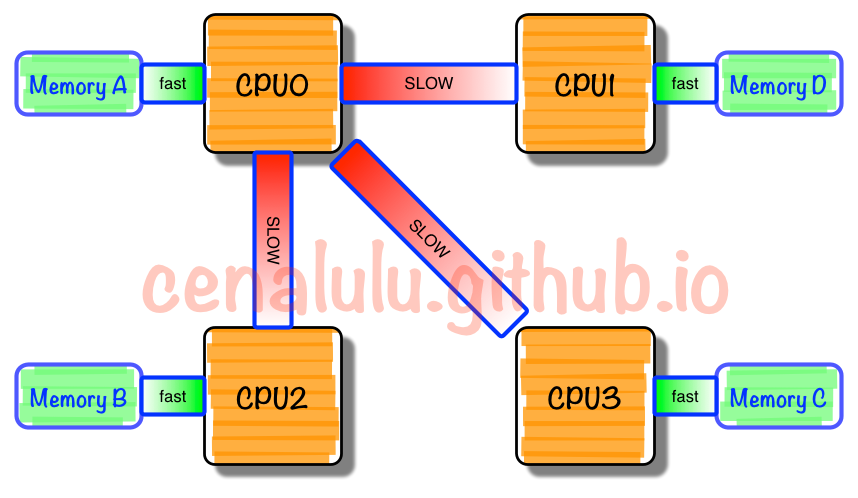
我们需要为 NUMA 做什么
假设你是 Linux 教父 Linus,对于 NUMA 架构你会做哪些优化?下面这点是显而易见的:
既然 CPU 只有在 Local-Access 时响应时间才能有保障,那么我们就尽量把该 CPU 所要的数据集中在他 local 的内存中就 OK 啦~
没错,事实上 Linux 识别到 NUMA 架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的 CPU 的 Local 内存上分配空间。如果 local 内存不足,优先淘汰 local 内存中无用的 Page(Inactive,Unmapped)。 那么,问题来了。。。
NUMA 的 “七宗罪”
几乎所有的运维都会多多少少被 NUMA 坑害过,让我们看看究竟有多少种在 NUMA 上栽的方式:
- MySQL – The MySQL “swap insanity” problem and the effects of the NUMA architecture
- PostgreSQL – PostgreSQL, NUMA and zone reclaim mode on linux
- Oracle – Non-Uniform Memory Access (NUMA) architecture with Oracle database by examples
- Java – Optimizing Linux Memory Management for Low-latency / High-throughput Databases
究其原因几乎都和:“因为 CPU 亲和策略导致的内存分配不平均” 及 “NUMA Zone Claim 内存回收” 有关,而和数据库种类并没有直接联系。所以下文我们就拿 MySQL 为例,来看看重内存操作应用在 NUMA 架构下到底会出现什么问题。
MySQL 在 NUMA 架构上会出现的问题
几乎所有 NUMA + MySQL 关键字的搜索结果都会指向:Jeremy Cole 大神的两篇文章
- The MySQL “swap insanity” problem and the effects of the NUMA architecture
- A brief update on NUMA and MySQL
大神解释的非常详尽,有兴趣的读者可以直接看原文。博主这里做一个简单的总结:
- CPU 规模因摩尔定律指数级发展,而总线发展缓慢,导致多核 CPU 通过一条总线共享内存成为瓶颈
- 于是 NUMA 出现了,CPU 平均划分为若干个 Chip(不多于 4 个),每个 Chip 有自己的内存控制器及内存插槽
- CPU 访问自己 Chip 上所插的内存时速度快,而访问其他 CPU 所关联的内存(下文称 Remote Access)的速度相较慢三倍左右
- 于是 Linux 内核默认使用 CPU 亲和的内存分配策略,使内存页尽可能的和调用线程处在同一个 Core/Chip 中
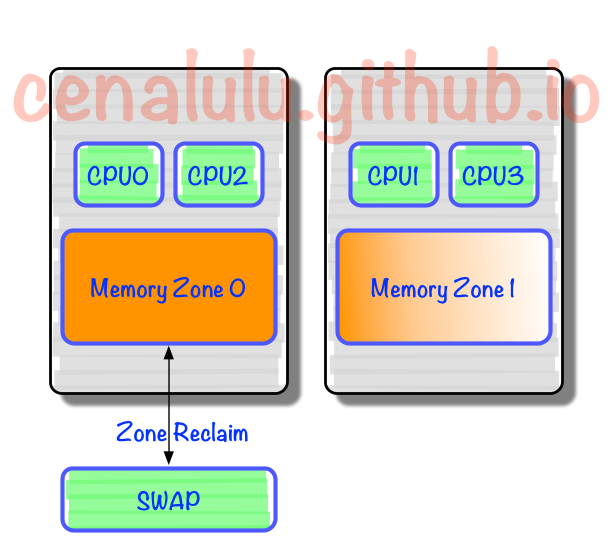
- 由于内存页没有动态调整策略,使得大部分内存页都集中在 CPU 0 上
- 又因为 Reclaim 默认策略优先淘汰 / Swap 本 Chip 上的内存,使得大量有用内存被换出
- 当被换出页被访问时问题就以数据库响应时间飙高甚至阻塞的形式出现了
解决方案
Jeremy Cole 大神推荐的三个方案如下,如果想详细了解可以阅读 原文
- numactl –interleave=all
- 在 MySQL 进程启动前,使用 sysctl -q -w vm.drop_caches=3 清空文件缓存所占用的空间
- Innodb 在启动时,就完成整个 Innodb_buffer_pool_size 的内存分配
这三个方案也被业界普遍认可可行,同时在 Twitter 的 5.5patch 和 Percona 5.5 Improved NUMA Support 中作为功能被支持。
不过这种三合一的解决方案只是减少了 NUMA 内存分配不均,导致的 MySQL SWAP 问题出现的可能性。如果当系统上其他进程,或者 MySQL 本身需要大量内存时,Innodb Buffer Pool 的那些 Page 同样还是会被 Swap 到存储上。于是又在这基础上出现了另外几个进阶方案
- 配置 vm.zone_reclaim_mode = 0 使得内存不足时去remote memory分配优先于 swap out local page
- echo -15 > /proc/
/oom_adj 调低 MySQL 进程被 OOM_killer 强制 Kill 的可能 - memlock
- 对 MySQL 使用 Huge Page(黑魔法,巧用了 Huge Page 不会被 swap 的特性)
重新审视问题
如果本文写到这里就这么结束了,那和搜索引擎结果中大量的 Step-by-Step 科普帖没什么差别。虽然我们用了各种参数调整减少了问题发生概率,那么真的就彻底解决了这个问题么?问题根源究竟是什么?让我们回过头来重新审视下这个问题:
NUMA Interleave 真的好么?
为什么 Interleave 的策略就解决了问题? 借用两张 Carrefour 性能测试 的结果图,可以看到几乎所有情况下 Interleave 模式下的程序性能都要比默认的亲和模式要高,有时甚至能高达 30%。究其根本原因是 Linux 服务器的大多数 workload 分布都是随机的:即每个线程在处理各个外部请求对应的逻辑时,所需要访问的内存是在物理上随机分布的。而 Interleave 模式就恰恰是针对这种特性将内存 page 随机打散到各个 CPU Core 上,使得每个 CPU 的负载和 Remote Access 的出现频率都均匀分布。相较 NUMA 默认的内存分配模式,死板的把内存都优先分配在线程所在 Core 上的做法,显然普遍适用性要强很多。
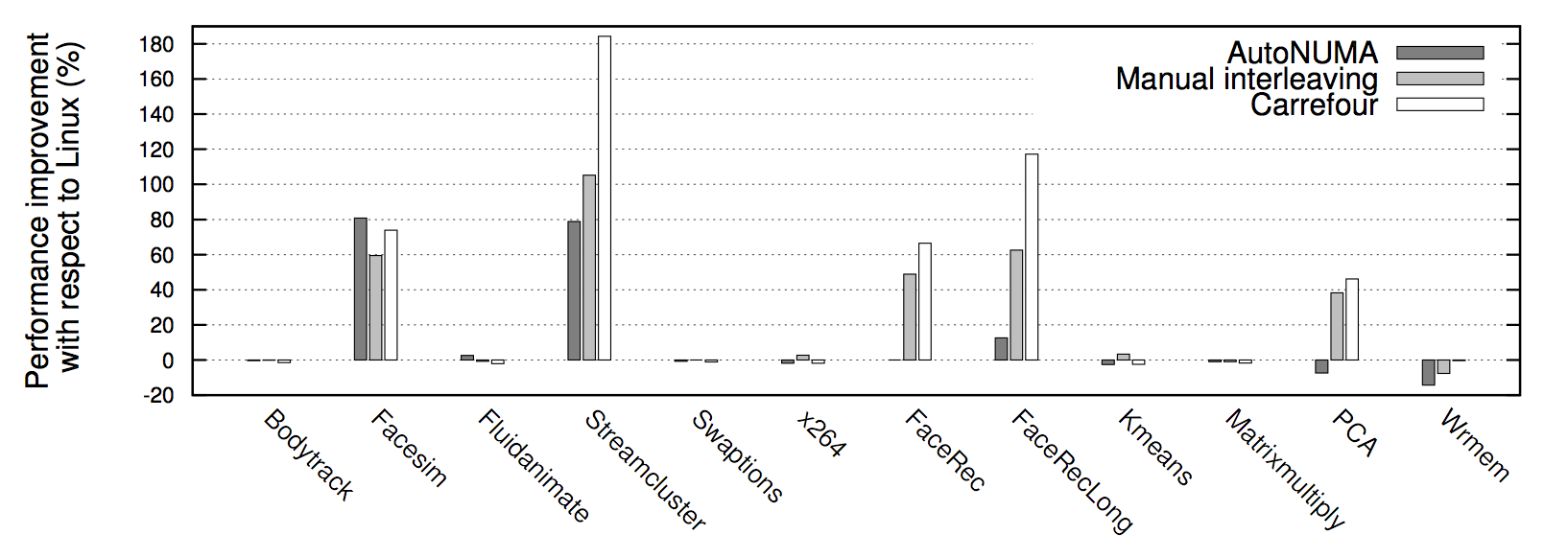
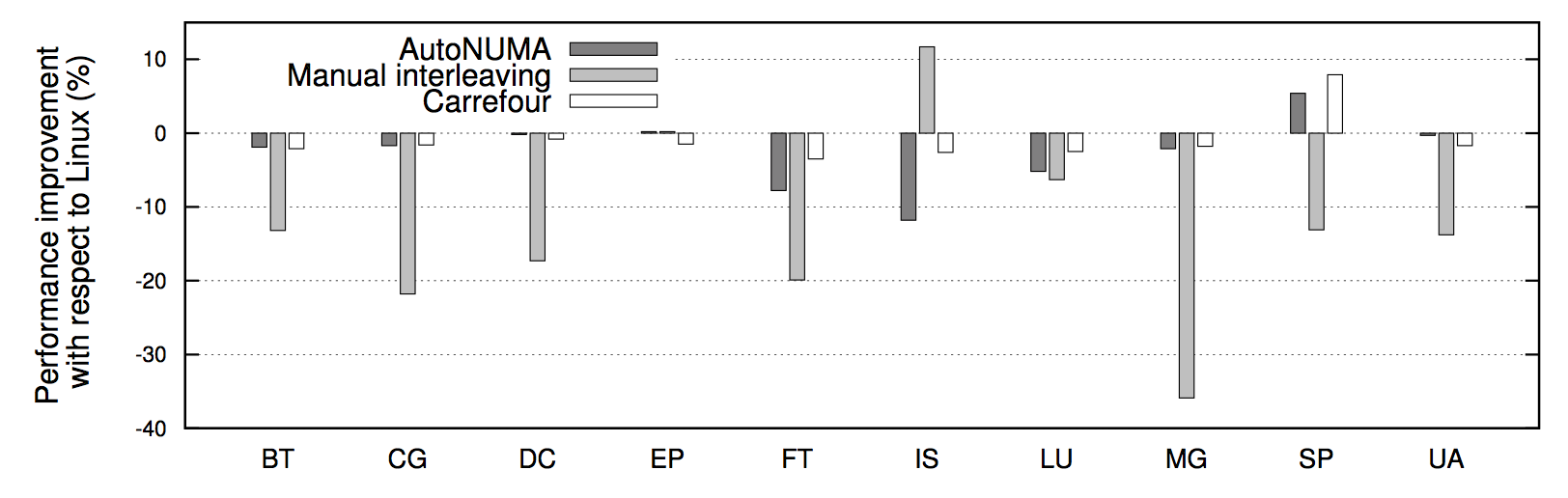
也就是说,像 MySQL 这种外部请求随机性强,各个线程访问内存在地址上平均分布的这种应用,Interleave 的内存分配模式相较默认模式可以带来一定程度的性能提升。 此外 各种 论文 中也都通过实验证实,真正造成程序在 NUMA 系统上性能瓶颈的并不是 Remote Acess 带来的响应时间损耗,而是内存的不合理分布导致 Remote Access 将 inter-connect 这个小水管塞满所造成的结果。而 Interleave 恰好,把这种不合理分布情况下的 Remote Access 请求平均分布在了各个小水管中。所以这也是 Interleave 效果奇佳的一个原因。
那是不是简简单单的配置个 Interleave 就已经把 NUMA 的特性和性能发挥到了极致呢? 答案是否定的,目前 Linux 的内存分配机制在 NUMA 架构的 CPU 上还有一定的改进空间。例如:Dynamic Memory Relocation, Page Replication。
Dynamic Memory Relocation 我们来想一下这个情况:MySQL 的线程分为两种,用户线程(SQL 执行线程)和内部线程(内部功能,如:flush,io,master 等)。对于用户线程来说随机性相当的强,但对于内部线程来说他们的行为以及所要访问的内存区域其实是相对固定且可以预测的。如果能对于这把这部分内存集中到这些内存线程所在的 core 上的时候,就能减少大量 Remote Access,潜在的提升例如 Page Flush,Purge 等功能的吞吐量,甚至可以提高 MySQL Crash 后 Recovery 的速度(由于 recovery 是单线程)。 那是否能在 Interleave 模式下,把那些明显应该聚集在一个 CPU 上的内存集中在一起呢? 很可惜,Dynamic Memory Relocation 这种技术目前只停留在理论和实验阶段。我们来看下难点:要做到按照线程的行为动态的调整 page 在 memory 的分布,就势必需要做线程和内存的实时监控(profile)。对于 Memory Access 这种非常异常频繁的底层操作来说增加 profile 入口的性能损耗是极大的。在 关于 CPU Cache 程序应该知道的那些事的评论中我也提到过,这个道理和为什么 Linux 没有全局监控 CPU L1/L2 Cache 命中率工具的原因是一样的。当然优化不会就此停步。上文提到的 Carrefour 算法和 Linux 社区的 Auto NUMA patch 都是积极的尝试。什么时候内存 profile 出现硬件级别,类似于 CPU 中 PMU 的功能时,动态内存规划就会展现很大的价值,甚至会作为 Linux Kernel 的一个内部功能来实现。到那时我们再回过头来审视这个方案的实际价值。
Page Replication 再来看一下这些情况:一些动态加载的库,把他们放在任何一个线程所在的 CPU 都会导致其他 CPU 上线程的执行效率下降。而这些共享数据往往读写比非常高,如果能把这些数据的副本在每个 Memory Zone 内都放置一份,理论上会带来较大的性能提升,同时也减少在 inter-connect 上出现的瓶颈。实时上,仍然是上文提到的 Carrefour 也做了这样的尝试。由于缺乏硬件级别(如 MESI 协议的硬件支持)和操作系统原生级别的支持,Page Replication 在数据一致性上维护的成本显得比他带来的提升更多。因此这种尝试也仅仅停留在理论阶段。当然,如果能得到底层的大力支持,相信这个方案还是有极大的实际价值的。
究竟是哪里出了问题
NUMA 的问题? NUMA 本身没有错,是 CPU 发展的一种必然趋势。但是 NUMA 的出现使得操作系统不得不关注内存访问速度不平均的问题。
Linux Kernel 内存分配策略的问题? 分配策略的初衷是好的,为了内存更接近需要他的线程,但是没有考虑到数据库这种大规模内存使用的应用场景。同时缺乏动态调整的功能,使得这种悲剧在内存分配的那一刻就被买下了伏笔。
数据库设计者不懂 NUMA? 数据库设计者也许从一开始就不会意识到 NUMA 的流行,或者甚至说提供一个透明稳定的内存访问是操作系统最基本的职责。那么在现状改变非常困难的情况下(下文会提到为什么困难)是不是作为内存使用者有义务更好的去理解使用 NUMA?
总结
其实无论是 NUMA 还是 Linux Kernel,亦或是程序开发他们都没有错,只是还做得不够极致。如果 NUMA 在硬件级别可以提供更多低成本的 profile 接口;如果 Linux Kernel 可以使用更科学的动态调整策略;如果程序开发人员更懂 NUMA,那么我们完全可以更好的发挥 NUMA 的性能,使得无限横向扩展 CPU 核数不再是一个梦想。
- Percona NUMA aware Configuration
- Numa system performance issues – more than just swapping to consider
- MySQL Server and NUMA architectures
- Checking /proc/pid/numa_maps can be dangerous for mysql client connections
- on swapping and kernels
- Optimizing Linux Memory Management for Low-latency / High-throughput Databases
- Memory System Performance in a NUMA Multicore Multiprocessor
- A Case for NUMA-aware Contention Management on Multicore Systems
文档信息
- 本文作者:Lewin
- 本文链接:https://lewinz.com/2022/01/28/cpu-numa/
- 版权声明:自由转载-非商用-非衍生-保持署名