unsafe 包简单说明
unsafe,顾名思义,是不安全的,Go 定义这个包名也是这个意思,让我们尽可能的不要使用它,如果你使用它,看到了这个名字,也会想到尽可能的不要使用它,或者更小心的使用它。
使用 unsafe 包的同时也放弃了 Go 语言保证与未来版本的兼容性的承诺,因为它必然会有意无意中使用很多非公开的实现细节,而这些实现的细节在未来的 Go 语言中很可能会被改变。 unsafe 包被广泛地用于比较低级的包,例如 runtime、os、syscall 还有 net 包等,因为它们需要和操作系统密切配合,但是对于普通的程序一般是不需要使用 unsafe 包的。
虽然这个包不安全,但是它也有它的优势,那就是可以绕过 Go 的内存安全机制,直接对内存进行读写,所以有时候因为性能的需要,会冒一些风险使用该包,对内存进行操作。
unsafe.Sizeof 函数
Sizeof 函数返回操作数在内存中的字节大小(返回该类型所占用的内存大小),参数可以是任意类型的表达式,但是它并不会对表达式进行求值。
一个 Sizeof 函数调用是一个对应 uintptr 类型的常量表达式,因此返回的结果可以用作数组类型的长度大小,或者用作计算其他的常量。
Sizeof 函数可以返回一个类型所占用的内存大小,这个大小只有类型有关,和类型对应的变量存储的内容大小无关,比如 bool 型占用一个字节、int8 也占用一个字节。
import "unsafe"
func main() {
fmt.Println(unsafe.Sizeof("true")) // 16
fmt.Println(unsafe.Sizeof(true)) // 1
fmt.Println(unsafe.Sizeof(int8(0))) // 1
fmt.Println(unsafe.Sizeof(int16(10))) // 2
fmt.Println(unsafe.Sizeof(int32(10000000))) // 4
fmt.Println(unsafe.Sizeof(int64(10000000000000))) // 8
fmt.Println(unsafe.Sizeof(int(1))) // 8
fmt.Println(unsafe.Sizeof(float64(0))) // 8
}
对于整型来说,占用的字节数意味着这个类型存储数字范围的大小,比如 int8 占用一个字节,也就是 8bit,所以它可以存储的大小范围是 - 128~~127, 也就是−2^(n-1) 到 2^(n-1)−1,n 表示 bit,int8 表示 8bit,int16 表示 16bit,其他以此类推。
对于和平台有关的 int 类型,这个要看平台是 32 位还是 64 位,会取最大的。比如我自己测试,以上输出,会发现 int 和 int64 的大小是一样的,因为我的是 64 位平台的电脑。
func Sizeof(x ArbitraryType) uintptr
以上是 Sizeof 的函数定义,它接收一个 ArbitraryType 类型的参数,返回一个 uintptr 类型的值。这里的 ArbitraryType 不用关心,他只是一个占位符,为了文档的考虑导出了该类型,但是一般不会使用它,我们只需要知道它表示任何类型,也就是我们这个函数可以接收任意类型的数据。
// ArbitraryType is here for the purposes of documentation only and is not actually
// part of the unsafe package. It represents the type of an arbitrary Go expression.
type ArbitraryType int
Alignof 函数
Alignof 返回一个类型的对齐值,也可以叫做对齐系数或者对齐倍数。对齐值是一个和内存对齐有关的值,合理的内存对齐可以提高内存读写的性能。
func main() {
var b bool
var i8 int8
var i16 int16
var i64 int64
var f32 float32
var s string
var m map[string]string
var p *int32
fmt.Println(unsafe.Alignof(b)) // 1
fmt.Println(unsafe.Alignof(i8)) // 1
fmt.Println(unsafe.Alignof(i16)) // 2
fmt.Println(unsafe.Alignof(i64)) // 8
fmt.Println(unsafe.Alignof(f32)) // 4
fmt.Println(unsafe.Alignof(s)) // 8
fmt.Println(unsafe.Alignof(m)) // 8
fmt.Println(unsafe.Alignof(p)) // 8
}
从以上例子的输出,可以看到,对齐值一般是 2^n, 最大不会超过 8(原因见下面的内存对齐规则)。Alignof 的函数定义和 Sizeof 基本上一样。这里需要注意的是每个人的电脑运行的结果可能不一样,大同小异。
func Alignof(x ArbitraryType) uintptr
获取对齐值还可以使用反射包的函数,也就是说:unsafe.Alignof (x) 等价于 reflect.TypeOf (x).Align ()。
Offsetof 函数
Offsetof 函数只适用于 struct 结构体中的字段相对于结构体的内存位置偏移量。结构体的第一个字段的偏移量都是 0。
func main() {
var u1 user1
fmt.Println(unsafe.Offsetof(u1.b)) // 0
fmt.Println(unsafe.Offsetof(u1.i)) // 4
fmt.Println(unsafe.Offsetof(u1.j)) // 8
fmt.Println(unsafe.Sizeof(u1)) // 16
}
type user1 struct {
b byte
i int32
j int64
}
字段的偏移量,就是该字段在 struct 结构体内存布局中的起始位置 (内存位置索引从 0 开始)。
根据字段的偏移量,我们可以定位结构体的字段,进而可以读写该结构体的字段,哪怕他们是私有的。这里可以直接用汇编获取对应偏移量的字段值。
同样也可以用反射表示:
unsafe.Offsetof (u1.i) 等价于 reflect.TypeOf (u1).Field (i).Offset
struct 字段顺序不同,最终大小可能不同
首先来看个栗子:
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
来看一下 Part1 共占用的大小是多少呢?
func main() {
fmt.Printf("bool size: %d\n", unsafe.Sizeof(bool(true)))
fmt.Printf("int32 size: %d\n", unsafe.Sizeof(int32(0)))
fmt.Printf("int8 size: %d\n", unsafe.Sizeof(int8(0)))
fmt.Printf("int64 size: %d\n", unsafe.Sizeof(int64(0)))
fmt.Printf("byte size: %d\n", unsafe.Sizeof(byte(0)))
fmt.Printf("string size: %d\n", unsafe.Sizeof("EDDYCJY"))
}
结果如下:
bool size: 1
int32 size: 4
int8 size: 1
int64 size: 8
byte size: 1
string size: 16
然后你也许就会得出这个结果:
Part1 这一个结构体的占用内存大小为 1+4+1+8+1 = 15 个字节。相信有的小伙伴是这么算的,看上去也没什么毛病
但是实际答案却是:
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
func main() {
part1 := Part1{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
}
输出结果:
part1 size: 32, align: 8
最终输出为占用 32 个字节。这与前面所预期的结果完全不一样。这充分地说明了先前的计算方式是错误的。
为什么呢?
在这里要提到 “内存对齐” 这一概念,才能够用正确的姿势去计算,接下来我们详细的讲讲它是什么
内存对齐
有的小伙伴可能会认为内存读取,就是一个简单的字节数组摆放

上图表示一个坑一个萝卜的内存读取方式。但实际上 CPU 并不会以一个一个字节去读取和写入内存。
敲重点啦:
相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。块大小我们称其为内存访问粒度。如下图:
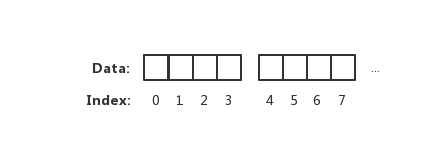
在样例中,假设访问粒度为 4。 CPU 是以每 4 个字节大小的访问粒度去读取和写入内存的。这才是正确的姿势
为什么要关心对齐?
- 你正在编写的代码在性能(CPU、Memory)方面有一定的要求
- 你正在处理向量方面的指令
- 某些硬件平台(ARM)体系不支持未对齐的内存访问
为什么要做对齐
平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
性能原因:若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作
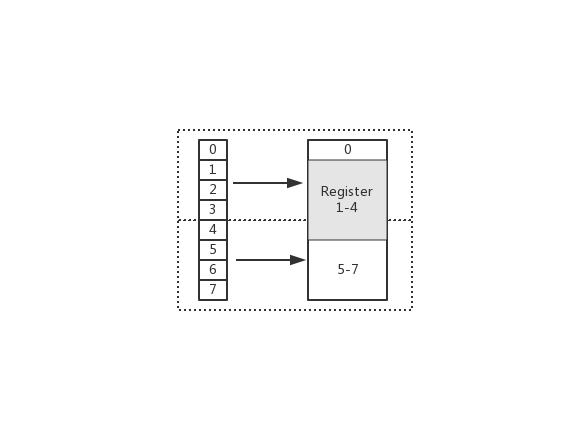
在上图中,假设从 Index 1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。因此 CPU 会做一些额外的处理工作。如下:
- CPU 首次读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
- CPU 再次读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
- 合并 1-4 字节的数据
- 合并后放入寄存器
从上述流程可得出,不做 “内存对齐” 是一件有点 “麻烦” 的事。因为它会增加许多耗费时间的动作
而假设做了内存对齐,从 Index 0 开始读取 4 个字节,只需要读取一次,也不需要额外的运算。
这显然高效很多,是标准的空间换时间做法
默认对齐系数
在不同平台上的编译器都有自己默认的 “对齐系数”,可通过预编译命令 #pragma pack (n) 进行变更,n 就是代指 “对齐系数”。一般来讲,我们常用的平台的系数如下:
- 32 位:4
- 64 位:8
另外要注意,不同硬件平台占用的大小和对齐值都可能是不一样的。因此本文的值不是唯一的,调试的时候需按本机的实际情况考虑
成员对齐
func main() {
fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
}
bool align: 1
int32 align: 4
int8 align: 1
int64 align: 8
byte align: 1
string align: 8
map align: 8
关于 unsafe.Alignof 是用来来返回相应类型的对齐系数,上面已经说了。
通过观察输出结果,可得知基本都是 2^n,最大也不会超过 8。这是因为我本机(64 位)编译器默认对齐系数是 8,因此最大值不会超过这个数
整体对齐 (结构体本身也要对齐)
上面提到了结构体中的成员变量要做字节对齐。那么想当然身为最终结果的结构体,也是需要做字节对齐的
对齐规则
结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度(#pragma pack (n))或当前成员变量类型的长度(unsafe.Sizeof),取最小值作为当前类型的对齐值。其偏移量必须为对齐值的整数倍
结构体本身,对齐值必须为编译器默认对齐长度(#pragma pack (n))或结构体的所有成员变量类型中的最大长度,取最大数的最小整数倍作为对齐值
结合以上两点,可得知若编译器默认对齐长度(#pragma pack (n))超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
换个说法就是:
对于具体类型来说,对齐值 = min (编译器默认对齐值,类型大小 Sizeof 长度)。也就是在默认设置的对齐值和类型的内存占用大小之间,取最小值为该类型的对齐值。我的电脑默认是 8,所以最大值不会超过 8.
struct 在每个字段都内存对齐之后,其本身也要进行对齐,对齐值 = min (默认对齐值,字段最大类型长度)。这条也很好理解,struct 的所有字段中,最大的那个类型的长度以及默认对齐值之间,取最小的那个。
分析流程
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
| 成员变量 | 类型 | 偏移量 | 自身占用 |
|---|---|---|---|
| a | bool | 0 | 1 |
| 字节对齐 | 无 | 1 | 3 |
| b | int32 | 4 | 4 |
| c | int8 | 8 | 1 |
| 字节对齐 | 无 | 9 | 7 |
| d | int64 | 16 | 8 |
| e | byte | 24 | 1 |
| 字节对齐 | 无 | 25 | 7 |
| 总占用大小 | - | - 32 |
成员对齐:
- 第一个成员 a
- 类型为 bool
- 对齐值为 1 字节
- 初始地址,偏移量为 0。占用了第 1 位
- 第二个成员 b
- 类型为 int32
- 大小 / 对齐值为 4 字节
根据规则 1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此 2-4 位为 Padding。而当前数值从第 5 位开始填充,到第 8 位。如下:axxx bbbb
- 第三个成员 c
- 类型为 int8
- 大小 / 对齐值为 1 字节
根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 8。不需要额外对齐,填充 1 个字节到第 9 位。如下:axxx bbbb c…
- 第四个成员 d
- 类型为 int64
- 大小 / 对齐值为 8 字节
根据规则 1,其偏移量必须为 8 的整数倍。确定偏移量为 16,因此 9-16 位为 Padding。而当前数值从第 17 位开始写入,到第 24 位。如下:axxx bbbb cxxx xxxx dddd dddd
- 第五个成员 e
- 类型为 byte
- 大小 / 对齐值为 1 字节
根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 24。不需要额外对齐,填充 1 个字节到第 25 位。如下:axxx bbbb cxxx xxxx dddd dddd e…
整体对齐:
在每个成员变量进行对齐后,根据规则 2,整个结构体本身也要进行字节对齐,因为可发现它可能并不是 2^n,不是偶数倍。显然不符合对齐的规则
根据规则 2,可得出对齐值为 8。现在的偏移量为 25,不是 8 的整倍数。因此确定偏移量为 32。对结构体进行对齐
结果: Part1 内存布局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
其中 xxx 表示为 “内存空洞”
推论字段顺序可改变结构体大小
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
e byte
c int8
a bool
b int32
d int64
}
func main() {
part1 := Part1{}
part2 := Part2{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Printf("part2 size: %d, align: %d\n", unsafe.Sizeof(part2), unsafe.Alignof(part2))
}
part1 size: 32, align: 8
part2 size: 16, align: 8
分析过程和上面完全一样。
文档信息
- 本文作者:Lewin
- 本文链接:https://lewinz.com/2021/11/21/golang-memory-alignment/
- 版权声明:自由转载-非商用-非衍生-保持署名