背景
2017 年时序数据库忽然火了起来。开年 2 月 Facebook 开源了 beringei 时序数据库;到了 4 月基于 PostgreSQL 打造的时序数据库 TimeScaleDB 也开源了,而早在 2016 年 7 月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品 TSDB,成为支持其发展制造,交通,能源,智慧城市等产业领域的核心产品,同时也成为百度战略发展产业物联网的标志性事件。
时间序列数据库 Time Series Database (TSDB)
随着分布式系统监控、物联网的发展,TSDB 开始受到更多的关注。 维基百科上对于时间序列的定义是‘一系列数据点按照时间顺序排列’
时间序列数据就是历史烙印,具有不变性,、唯一性、时间排序性
时间序列数据跟关系型数据库有太多不同,但是很多公司并不想放弃关系型数据库。 于是就产生了一些特殊的用法,比如用 MySQL 的 VividCortex, 用 Postgres 的 Timescale。 很多人觉得特殊的问题需要特殊的解决方法,于是很多时间序列数据库从头写起,不依赖任何现有的数据库, 比如 Graphite,InfluxDB。
mysql 的引擎,除了常见的 innodb 和 myisam ,还有一个引擎叫 archive ,它的作用和 rrd 差不多,支持插入和查询操作。
- 时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
- 时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
数据写入的特点
- 写入平稳、持续、高并发高吞吐:时序数据的写入是比较平稳的,这点与应用数据不同,应用数据通常与应用的访问量成正比,而应用的访问量通常存在波峰波谷。时序数据的产生通常是以一个固定的时间频率产生,不会受其他因素的制约,其数据生成的速度是相对比较平稳的。
- 写多读少:时序数据上 95%-99%的操作都是写操作,是典型的写多读少的数据。这与其数据特性相关,例如监控数据,你的监控项可能很多,但是你真正去读的可能比较少,通常只会关心几个特定的关键指标或者在特定的场景下才会去读数据。
- 实时写入最近生成的数据,无更新:时序数据的写入是实时的,且每次写入都是最近生成的数据,这与其数据生成的特点相关,因为其数据生成是随着时间推进的,而新生成的数据会实时的进行写入。数据写入无更新,在时间这个维度上,随着时间的推进,每次数据都是新数据,不会存在旧数据的更新,不过不排除人为的对数据做订正。
数据查询和分析的特点
- 按时间范围读取:通常来说,你不会去关心某个特定点的数据,而是一段时间的数据。
- 最近的数据被读取的概率高
- 历史数据粗粒度查询的概率搞
- 多种精度查询
- 多维度分析
数据存储的特点
- 数据量大:拿监控数据来举例,如果我们采集的监控数据的时间间隔是 1s,那一个监控项每天会产生 86400 个数据点,若有 10000 个监控项,则一天就会产生 864000000 个数据点。在物联网场景下,这个数字会更大。整个数据的规模,是 TB 甚至是 PB 级的。
- 冷热分明:时序数据有非常典型的冷热特征,越是历史的数据,被查询和分析的概率越低。
- 具有时效性:时序数据具有时效性,数据通常会有一个保存周期,超过这个保存周期的数据可以认为是失效的,可以被回收。一方面是因为越是历史的数据,可利用的价值越低;另一方面是为了节省存储成本,低价值的数据可以被清理。
- 多精度数据存储:在查询的特点里提到时序数据出于存储成本和查询效率的考虑,会需要一个多精度的查询,同样也需要一个多精度数据的存储。
开源时间序列数据库
- 1999/07/16 RRDTool First release
- 2009/12/30 Graphite 0.9.5
- 2011/12/23 OpenTSDB 1.0.0
- 2013/05/24 KairosDB 1.0.0-beta
- 2013/10/24 InfluxDB 0.0.1
- 2014/08/25 Heroic 0.3.0
- 2017/03/27 TimescaleDB 0.0.1-beta
RRDTool 是最早的时间序列数据库,它自带画图功能,现在大部分时间序列数据库都使用 Grafana 来画图。
Graphite 是用 Python 写的 RRD 数据库,它的存储引擎 Whisper 也是 Python 写的, 它画图和聚合能力都强了很多,但是很难水平扩展。
OpenTSDB 使用 HBase 解决了水平扩展的问题
KairosDB 最初是基于 OpenTSDB 修改的,但是作者认为兼容 HBase 导致他们不能使用很多 Cassandra 独有的特性, 于是就抛弃了 HBase 仅支持 Cassandra。
新发布的 OpenTSDB 中也加入了对 Cassandra 的支持。 故事还没完,Spotify 的人本来想使用 KairosDB,但是觉得项目发展方向不对以及性能太差,就自己撸了一个 Heroic。
InfluxDB 早期是完全开源的,后来为了维持公司运营,闭源了集群版本。 在 Percona Live 上他们做了一个开源数据库商业模型正面临危机的演讲,里面调侃红帽的段子很不错。 并且今年的 Percona Live 还有专门的时间序列数据库单元。
数据模型
时间序列数据可以分成两部分
- 序列 :就是标识符(维度),主要的目的是方便进行搜索和筛选
- 数据点:时间戳和数值构成的数组
- 行存:一个数组包含多个点,如 [{t: 2017-09-03-21:24:44, v: 0.1002}, {t: 2017-09-03-21:24:45, v: 0.1012}]
- 列存:两个数组,一个存时间戳,一个存数值,如[ 2017-09-03-21:24:44, 2017-09-03-21:24:45], [0.1002, 0.1012]
一般情况下:列存能有更好的压缩率和查询性能
基本概念
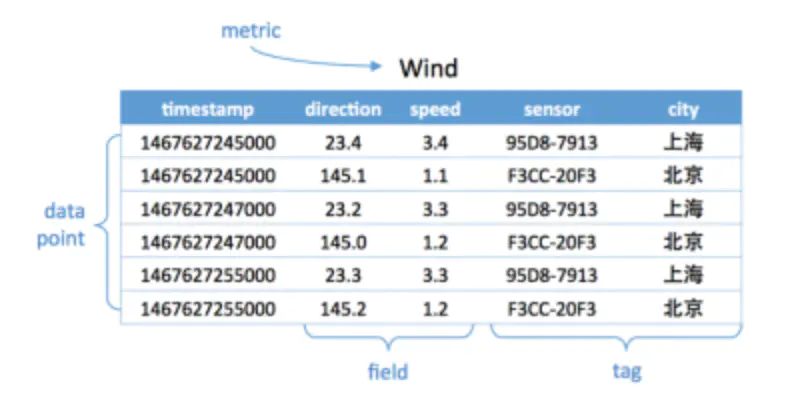
- metric: 度量,相当于关系型数据库中的 table。
- data point: 数据点,相当于关系型数据库中的 row。
- timestamp:时间戳,代表数据点产生的时间。
- field: 度量下的不同字段。比如位置这个度量具有经度和纬度两个 field。一般情况下存放的是会随着时间戳的变化而变化的数据。
- tag: 标签,或者附加信息。一般存放的是并不随着时间戳变化的属性信息。timestamp 加上所有的 tags 可以认为是 table 的 primary key。
如下图,度量为 Wind,每一个数据点都具有一个 timestamp,两个 field:direction 和 speed,两个 tag:sensor、city。它的第一行和第三行,存放的都是 sensor 号码为 95D8-7913 的设备,属性城市是上海。随着时间的变化,风向和风速都发生了改变,风向从 23.4 变成 23.2;而风速从 3.4 变成了 3.3。
应用场景
所有有时序数据产生,并且需要展现其历史趋势、周期规律、异常性的,进一步对未来做出预测分析的,都是时序数据库适合的场景。
例:
在工业物联网环境监控方向,百度天工的客户就遇到了这么一个难题,由于工业上面的要求,需要将工况数据存储起来。客户每个厂区具有 20000 个监测点,500 毫秒一个采集周期,一共 20 个厂区。这样算起来一年将产生惊人的 26 万亿个数据点。假设每个点 50Byte,数据总量将达 1P(如果每台服务器 10T 的硬盘,那么总共需要 100 多台服务器)。这些数据不只是要实时生成,写入存储;还要支持快速查询,做可视化的展示,帮助管理者分析决策;并且也能够用来做大数据分析,发现深层次的问题,帮助企业节能减排,增加效益。最终客户采用了百度天工的时序数据库方案,帮助他解决了难题。
(这个高逼格)
时序数据库遇到的挑战
很多人可能认为在传统关系型数据库上加上时间戳一列就能作为时序数据库。数据量少的时候确实也没问题,但少量数据是展现的纬度有限,细节少,可置信低,更加不能用来做大数据分析。很明显时序数据库是为了解决海量数据场景而设计的。
可以看到时序数据库需要解决以下几个问题
- 时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
- 时序数据的读取:又如何支持在秒级对上亿数据的分组聚合运算。
- 成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
这些问题不是用一篇文章就能含盖的,同时每个问题都可以从多个角度去优化解决。在这里只从数据存储这个角度来尝试回答如何解决大数据量的写入和读取。
RRD
RRD (Round Robin Database)数据库是一个环形的数据库,数据库由一个固定大小的数据文件来存放数据,此数据库不会像传统数据库一样为随着数据的增多而文件的大小也在增加,RRD 在创建好后其文件大小就固定,可以把它想像成一个圆,圆的众多直径把圆划分成一个个扇形,每个扇形就是可以存数据的槽位,每个槽位上被打上了一个时间戳,在圆心上有一个指针,随着时间的流逝,取回数据后,指针会负责把数据填充在相应的槽位上,当指针转了 360 度后,最开始的数据就会被覆盖,就这样 RRD 循环填充着数据。
- 源数据搜集:采用一些数据搜集工具,如脚本、shell 命令、SNMP 等工具在一定时间间隔里把数据搜集填充到 rrd 数据库中,这些需要数据搜集的对象叫 DS,一个 DS 里在一个时间里可以搜集的数据可以有多个,比如一个时间点上对网卡来说有进来的流量,也有流出的流量,所以这是 2 个数据成为一组数据。
- 临时存储:源数据获取到后是存放在一个数据库的一个临时区域,这些源数据叫做 PDP
- 分组-聚合:RRDTool 把这些 PDP 数据作为数据源通过分组、再利用聚合函数计算后把计算后的结果放在 RRD 数据库的时间槽 (time slot) 上,这些数据叫做 CDP,CDP 才是 RRDTool 绘图时真正打交道的数据,
- 在从源数据中取数据做聚合计算时会有一个挑选数据的基准,也就是说是以几个源数据为一组做聚合,根据现实需求的不同,对源数据可以很灵活的选择不同的时间段提取源数据,再聚合提取不同的聚合值,这样就产生不同组别的 CDP 数据,这些有以相同时间段挑选源数据及相同聚合函数计算的结果组成的数据就叫 RRA,所以根据挑选源数据的标准及采用的聚合函数的不同,RRA 可以有多组。
- DS:Data Source 数据源,用于定义搜集数据的工具所搜集数据的一些特性
- Time Solt:时间槽,用于存放通过聚合后的数据区域
- PDP:Primary Data Point 主数据节点,每个时间点产生的数据,即是搜集的源数据,没有做聚合的数据
- CDP(Consolidation Data Point 聚合数据节点):通过对获取的源数据分组、聚合计算后得到的数据叫 CDP,
- RRA(Round Robin Archive 轮转归档):以相同的分组、聚合函数计算后的 CDP 数据组就组成了 RRA
- Resolution(解析度):这是一个时间跨度,表示在做聚合计算时是以几个连续的 time slot 里的数据做聚合,在默认时 rrd 是以 300 秒的间隔产生一个 time slot。
- CF:Consolidation Function,合并函数或聚合函数,以 RRDTool 中有 AVERAGE、MAX、MIN、LAST4 种
以一个图来说明 PDP、CDP、RRA 之间的关系:
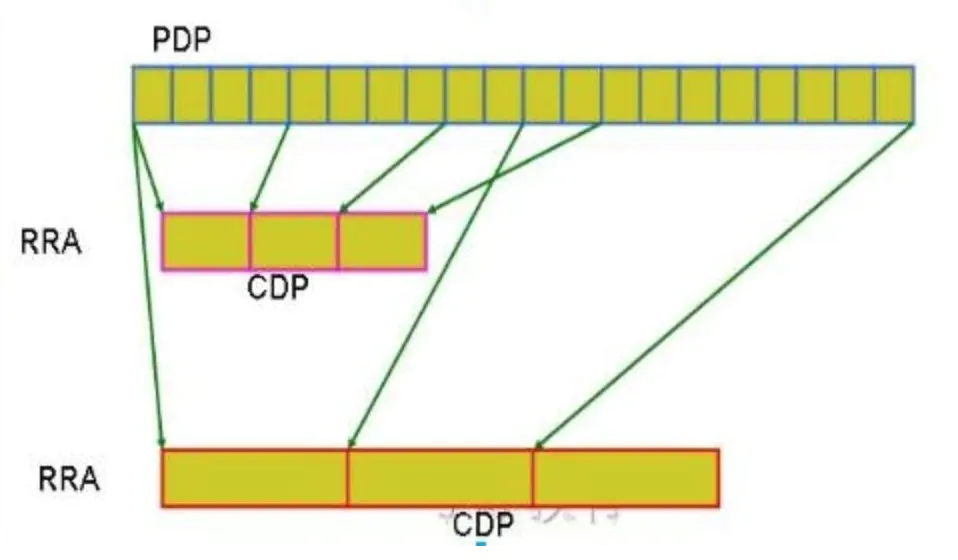
PDP 是以规定的时间间隔(默认为 300 秒)搜集的源数据,第一个 RRA 以 4 个 PDP(即 4*300 秒)为一组做 CF 后组成的数据,第二个 RRA 则是以 10 个 PDP 为一组做 CF 后组成的数据。
InfluxDB
InfluxDB 在存储引擎上纠结了很久, leveldb, rocksdb, boltdb 都玩了个遍,最后决定自己造个轮子叫 Time Structured Merge Tree。
Time Structured Merge Tree (TSM) 和 Log Structured Merge Tree (LSM) 的名字都有点误导性,关键并不是树,也不是日志或者时间,而是 Merge。
- 写入的时候,数据先写入到内存里,之后批量写入到硬盘。
- 读的时候,同时读内存和硬盘然后合并结果。
- 删除的时候,写入一个删除标记,被标记的数据在读取时不会被返回。
- 后台会把小的块合并成大的块,此时被标记删除的数据才真正被删除
- 相对于普通数据,有规律的时间序列数据在合并的过程中可以极大的提高压缩比。
文档信息
- 本文作者:Lewin
- 本文链接:https://lewinz.com/2021/05/30/time-series-database/
- 版权声明:自由转载-非商用-非衍生-保持署名