普罗米修斯 (Prometheus)
普罗米修斯 (Prometheus) 是一个 SoundCloud 公司开源的监控系统。当年,由于 SoundCloud 公司生产了太多的服务,传统的监控已经无法满足监控需求,于是他们在 2012 年决定着手开发新的监控系统,即普罗米修斯。
普罗米修斯(下称普罗)的作者 Matt T.Proud 在 2012 年加入 SoundCloud 公司,他从 google 的监控系统 Borgmon 中获得灵感,与另一名工程师 Julius Volz 合作开发了开源的普罗,后来其他开发人员陆续加入到该项目,最终于 2015 年正式发布。
普罗基于 Go 语言开发,其架构图如下: 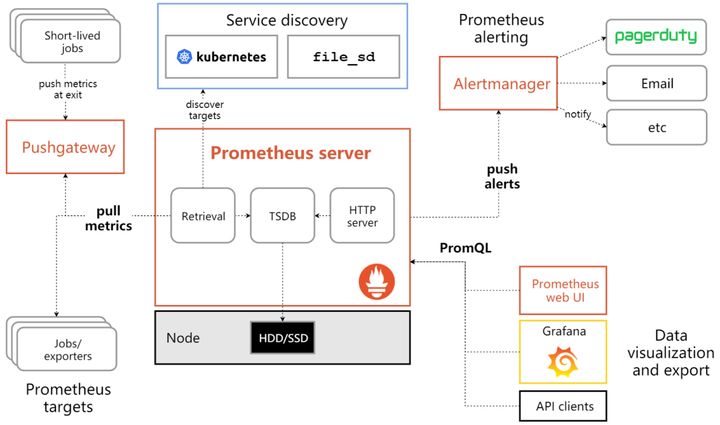
其中:
- Prometheus Server: 用数据的采集和存储,PromQL 查询,报警配置。
- Push gateway: 用于批量,短期的监控数据的汇报总节点。
- Exporters: 各种汇报数据的 exporter,例如汇报机器数据的 node_exporter,汇报 MondogDB 信息的 MongoDB_exporter 等等。
- Alertmanager: 用于高级通知管理。
采集监控数据
要采集目标(主机或服务)的监控数据,首先就要在被采集目标上安装采集组件,这种采集组件被称为 Exporter 。普罗米修斯 官网上有很多这种 exporter ,比如:
Consul exporter (official)
Memcached exporter (official)
MySQL server exporter (official)
Node/system metrics exporter (official)
HAProxy exporter (official)
RabbitMQ exporter
Grok exporter
InfluxDB exporter (official)
这些 exporter 能为我们采集目标的监控数据,然后传输给普罗米修斯。这时候,exporter 会暴露一个 http 接口,普罗米修斯通过 HTTP 协议使用 Pull 的方式周期性拉取相应的数据。
不过,普罗也提供了 Push 模式来进行数据传输,通过增加 Push Gateway 这个中间商实现,你可以将数据推送到 Push Gateway,普罗再通过 Pull 的方式从 Push Gateway 获取数据。
这就是为什么你从架构图里能看到两个 Pull metrics 的原因,一个是采集器直接被 Server 拉取数据 (pull);另一个是采集器主动 Push 数据到 Push Gateway,Server 再对 Push Gateway 主动拉取数据 (pull)。
采集数据的主要流程
Prometheus server 定期从静态配置的主机或服务发现的 targets 拉取数据(zookeeper,consul,DNS SRV Lookup 等方式)
当新拉取的数据大于配置内存缓存区的时候,Prometheus 会将数据持久化到磁盘,也可以远程持久化到云端。
Prometheus 通过 PromQL、API、Console 和其他可视化组件如 Grafana、Promdash 展示数据。
Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将告警推送到配置的 Alertmanager。
Alertmanager 收到告警的时候,会根据配置,聚合,去重,降噪,最后发出警告。
采集的数据结构与指标类型
数据结构
了解普罗米修斯的数据结构对于了解整个普罗生态非常重要。普罗采用键值对作为其基本的数据结构: 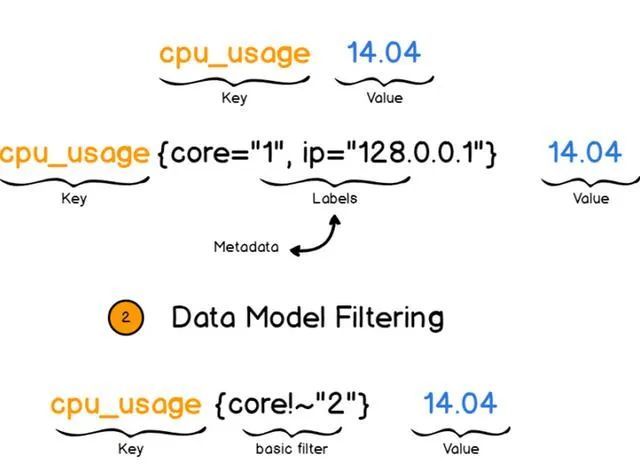
Key 是指标名字,Value 是该指标的值,此外 Metadata(元信息) 也非常重要,也可称之为 labels(标签信息)。这些标签信息指定了当前这个值属于哪个云区域下的哪台机器,如果没有 labels,数据有可能会被丢失。
指标类型
普罗米修斯的监控指标有 4 种基本类型:
Counter(计数器)
计数器是我们最简单的指标类型。比如你想统计某个网站的 HTTP 错误总数,这时候就用计数器。
计数器的值只能增加或重置为 0,因此特别适合计算某个时段上某个时间的发生次数,即指标随时间演变发生的变化。
Gauges
Gauges 可以用于处理随时间增加或减少的指标,比如内存变化、温度变化。
这可能是最常见的指标类型,不过它也有一定缺点:如果系统每 5 秒发送一次指标,普罗服务每 15 秒抓取一次数据,那么这期间可能会丢失一些指标,如果你基于这些数据做汇总分析计算,则结果的准确性会有所下滑。
Histogram(直方图)
直方图是一种更复杂的度量标准类型。它为我们的指标提供了额外信息,例如观察值的总和及其数量,常用于跟踪事件发生的规模。
比如,为了监控性能指标,我们希望在有 20%的服务器请求响应时间超过 300 毫秒时发送告警。对于涉及比例的指标就可以考虑使用直方图。
Summary(摘要)
摘要更高级一些,是对直方图的扩展。除了提供观察的总和和计数之外,它们还提供滑动窗口上的分位数度量。分位数是将概率密度划分为相等概率范围的方法。
对比直方图:
- 直方图随时间汇总值,给出总和和计数函数,使得易于查看给定指标的变化趋势。
- 而摘要则给出了滑动窗口上的分位数(即随时间不断变化)。
实例概念
随着分布式架构的不断发展和云解决方案的普及,现在的架构已经变得越来越复杂了。
分布式的服务器复制和分发成了日常架构的必备组件。我们举一个经典的 Web 架构,该架构由 3 个后端 Web 服务器组成。在该例子中,我们要监视 Web 服务器返回的 HTTP 错误的数量。
使用普罗米修斯语言,单个 Web 服务器单元称为实例(主机实例)。该任务是计算所有实例的 HTTP 错误数量。
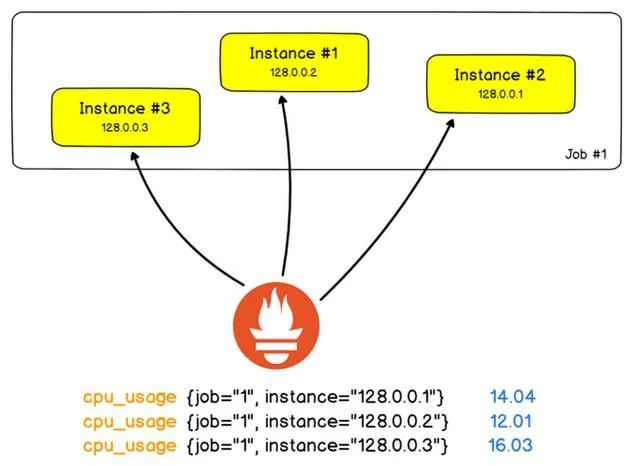
事实上,这甚至可以说是最简单的架构了,再复杂一点,实例不仅能是主机实例,还能是服务实例,因此你需要增加一个 instance_type 的标签标记主机或服务。
再再复杂一点,同样的 IP,可能存在于不同云区域下,这属于不同的机器,因此还需要一个 cloud 标签,最终该数据结构可能会变为:
cpu_usage {job=”1”, instance=”128.0.0.1”, cloud=”0”, instance_type=”0”}
数据可视化
如果使用过基于 InfluxDB 的数据库,你可能会熟悉 InfluxQL。普罗米修斯也内置了自己的 SQL 查询语言用于查询和检索数据,这个内置的语言就是 PromQL。
我们前面说过,普罗米修斯的数据是用键值对表示的。PromQL 也用相同的语法查询和返回结果集。
PromQL 会处理两种向量:
- 即时向量:表示当前时间,某个指标的数据向量。
- 时间范围向量:表示过去某时间范围内,某个指标的数据向量。
文档信息
- 本文作者:Lewin
- 本文链接:https://lewinz.com/2021/05/30/prometheus-info/
- 版权声明:自由转载-非商用-非衍生-保持署名